
Practices to Implement Right Now to Achieve True CICD
CICD is an acronym that is frequently misunderstood. The most common (mis)understanding we hear is something like, “We push our code to a branch and have Jenkins run all of the tests before we deploy. This is our CICD pipeline!” However, continuous integration (CI) and continuous delivery/deployment (CD) are two separate disciplines that are often conflated. CD cannot exist without CI, but CI without CD is a very common software development process.
Many teams believe they are practicing CICD when in fact they are not following some of its fundamental best practices. They are able to achieve bi-weekly releases and usually don’t have “fire drills” to address production issues after deployment. Most of the time, the team is able to find production problems before they are noticed by users. But does this mean CICD has been achieved? Read on to learn how to make the lives of your development teams, business stakeholders, and users easier by truly practicing CICD at your organization.
What is Continuous Integration?
CI stands for continuous integration. By definition, it is a DevOps software development practice where developers regularly merge their code changes into a central repository, after which automated builds and tests are run. These days, CI is a standard practice across the tech industry. To understand the benefits of CI, it may be helpful to explain what life was like for software teams before the introduction of continuous integration.
Life Before Continuous Integration
Before the adoption of CI and other agile methodology practices, engineering teams generally used a waterfall-style approach to software development, which typically involved longer development cycles and more manual testing and integration.
With this old-school approach, developers would work on their own code branches and make changes independently, often without coordinating with other team members. Integration would happen at a later stage of the development cycle, usually during a dedicated integration phase or testing phase. This meant that bugs and integration issues could go undetected for long periods of time, and fixing them would often require a significant amount of time and effort.
The lack of coordination and communication between team members could also lead to conflicts and delays in the development process. For example, if two developers made changes to the same code file without coordinating their efforts, it could create very large conflicts that would need to be resolved manually, which were often difficult to fix and ultimately delayed the integration process.
Software deployments were also performed manually. For example, a developer or system administrator might copy files from a development machine via file transfer protocol (FTP) to the server on which the application was running. This was a tedious, error-prone process. Much like the delayed integration and testing phases, delaying the deployment phase of development meant increasing the cost and effort required to fix problems.
Integrating, Continuously
To address these challenges, organizations began adopting CI as a software development practice in the early 2000s. By regularly integrating code changes and automatically running tests, CI helped to catch and fix integration problems early in the development cycle, reduce conflicts between team members, and speed up the overall development process.
Today, continuous integration has become a standard practice in software development, with many organizations using dedicated tools and platforms (see below under “How to Achieve Continuous Integration”) to automate the build, testing, and integration process.
It’s also important to define CI pipelines. A CI pipeline is the full set of processes that run when a developer pushes code to a shared code repository. At a minimum, this should be running a full suite of tests (end-to-end, integration, and unit) and performing a deployment to various environments such as pre-production and production. This could also include running static code analysis, publishing artifacts, publishing build and deployment notifications, calculating code coverage, vulnerability scans, and many more possibilities.
Shifting Left
In the mid-2010s, the idea of early integration of systems was expanded upon to include both automated testing and security practices as well. This movement is sometimes referred to as DevSecOps (development, security, and operations). As we outlined in our test-driven development-focused blog, the cost to fix bugs greatly increases over the course of the software development process. The same is true of fixing security vulnerabilities. By “shifting left”, software development teams can ensure faster feature delivery, solid integrations, and reduced security risks. Continuous integration platforms are an essential component of achieving the best possible results for a software project.
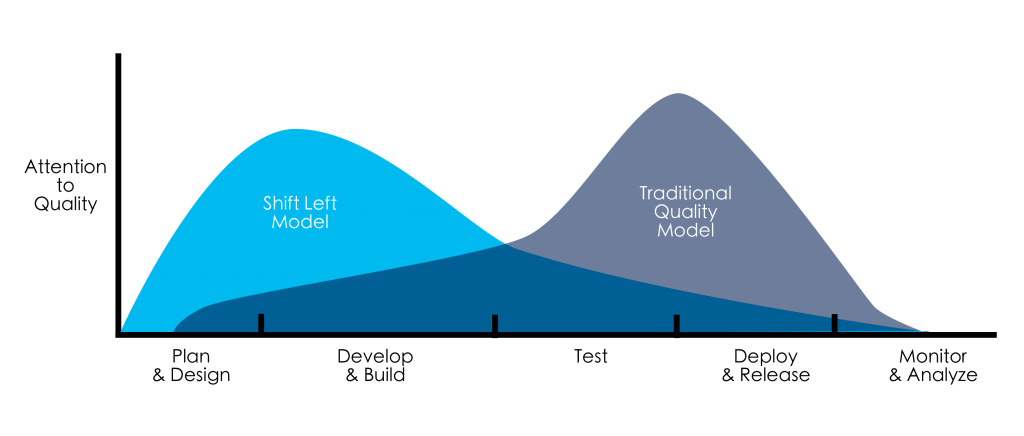
IMAGE SOURCE: HTTPS://DEVOPEDIA.ORG/SHIFT-LEFT CI for application development has been standard in the industry for quite some time. Infrastructure concerns, on the other hand, have been developed and deployed with a more manual approach until recently. With Infrastructure as Code tools (IaC) such as CloudFormation and Terraform, many of the benefits of CI (such as repeatable builds, the elimination of snowflake environments, and shared code repositories) can be realized for managing infrastructure. IaC and CICD are two of the three core components of GitOps. You can read more about GitOps here.
How to Achieve Continuous Integration
Source Control - The most important ingredient of a successful continuous integration pipeline is source control. These days, Git is practically the universal standard. Git enables individual developers to develop small, incremental changes in isolation and frequently integrate them into a shared repository. The more often these changes are integrated, the better. This concept also works well with Trunk-based development, which encourages small, frequent merges to minimize conflicts and risk.
Test Driven Development - By practicing TDD and having a good strategy for tests at various levels of the testing pyramid (end-to-end, integration, unit, performance), teams can minimize the chance of regressions while simultaneously delivering new functionality and enabling the ability to continuously refactor. Don’t forget to check out our TDD blog to learn more!
Automated Build Process - Teams should use an automated build platform (Github Actions, Jenkins, CircleCI, etc.) that allows the team to continuously build and test their application on each commit into the shared code repository. This platform can serve as a hub that will consistently notify teams of potential problems in the code base and allow them to monitor code health.
Automated Deployments - Deployments can usually be managed by the same system that performs the automated builds. Whether teams practice continuous delivery or continuous deployment, the process of software deployment should be as automated as possible.
In addition to the essential ingredients listed above, various projects may employ the following techniques depending on the experience level of the team and the needs of the project:
Code coverage metrics - Help you understand how much of the source code is tested, and precisely which code is tested and/or missing tests; Example: Jacoco for Java
Code complexity metrics - Quantitative measure of the number of linearly independent paths through a program's source code; Example: Cyclomatic complexity
Project dependency monitoring - Tools that point out the project dependencies that are outdated and/or contain known security vulnerabilities; Example: Renovate Bot
Vulnerability scans - Provide many of the same benefits as project dependency monitoring, but can also monitor dependencies such as docker images, computer networks, etc.; Example: Snyk
Chaos engineering - Method of testing distributed software that deliberately introduces failure and faulty scenarios to verify its resilience in the face of random disruptions
Static code analysis - Method of debugging that automatically examines the source code without having to execute the program, which can help identify issues such as programming errors, coding standards violations, syntax errors, and security vulnerabilities
Common Continuous Integration Anti-Patterns
Anti-patterns are common software engineering practices that may initially seem helpful but ultimately lead to less-than-optimal outcomes. If your team uses source control and you build and test your code on every commit, great! Your team is continuously integrating. Chances are, though, that you could greatly improve your process. Here are some common anti-patterns we’ve seen:
Slow and unreliable tests - If tests take a long time to run or are unreliable, it can slow down the CI process and reduce the effectiveness of automated testing. Slow or unreliable tests can also lead to developers bypassing the testing process altogether, which can increase the risk of bugs and issues in the code.
Manual deployment to testing environments - One of the key benefits of CI is the ability to automate the build, test, and deployment process. If developers need to manually intervene in the CI process, such as by manually triggering builds or deploying code to any environment, it can slow down the process and introduce the potential for human error. Manually deploying to environments greatly increases the time in the feedback loop to developers, which limits velocity, creates bottlenecks, and increases the risk of merge conflicts and integration problems.
Testing in isolation - Testing in isolation, such as only testing individual modules or components (relying solely on unit tests), can lead to issues that only arise when the code is integrated into the larger system. This can lead to bugs and issues that are only discovered later in the development process, which can be more difficult and expensive to fix.
Substantial manual QA - While it is common to have resources dedicated to QA, it is an antipattern to rely exclusively on manual testing. Manual QA is inefficient, and distracts those engineers from other value-add efforts like exploratory testing and building features.
Continuous build, occasional integration (CBOI) - This is, sadly, the most common implementation of CI, where you have CI running on your team’s code but you still regularly discover bugs in production. Perhaps you are building an application that is actually part of a software system. Your CI pipeline regularly tests your team’s code, but you frequently run into production problems because of an integration with another team’s codebase. This is a perfect example of CBOI. Tests that exercise the integration between teams, applications, and systems should be incorporated into a CI pipeline. Shift left on the integration so that you can discover problems early (i.e., before your customers do!)
Merging large feature branches - Merges should be as small and easily testable as possible. Merging an entire feature branch creates additional risk and larger conflicts to resolve.
What is Continuous Delivery/Deployment?
CD stands for both continuous delivery and continuous deployment. The goal of both continuous delivery and continuous deployment is the same: to enable the frequent and reliable delivery of software to production. It involves automating the entire software delivery process, from building, to testing, to deploying software to production environments, ensuring that software changes are delivered quickly and safely.
“A faster release tempo means less time to test changes before they are put in front of users. You might think this means a higher likelihood of production defects, but research has in fact shown the opposite—deploying more frequently has a positive relationship with both a lower change-failure rate and a lower mean time to recovery.”
To enable this method of software delivery, teams should build pipelines to automate the process. The pipeline will build the code, execute automated tests (unit, integration, e2e), execute any code health processes (code coverage, vulnerability scans), and deploy to QA, staging/integration, and production environments.
The difference between continuous delivery and continuous deployment is small in theory, but large in practice. Continuous delivery automates nearly the entire process of building and testing, but requires manual intervention before a production release. Continuous deployment removes this manual step so that the entire process is completely automated.

Crafted believes that every software development team should be striving for a continuous deployment model. Not every product can be fully automated to a production deployment (e.g., mobile applications that require approval from Google/Apple, software for hardware devices, regulatory requirements such as SOC2 and PCI, etc.), but in general, the process should be automated as fully as possible.
Removing the manual trigger to a production deployment to realize the transition from continuous delivery to continuous deployment is challenging and requires mature DevOps practices. Here are a few obstacles that need to be addressed:
Communication with stakeholders and customers - Stakeholders and other individuals in customer-facing roles like to know when new features are released so they can effectively communicate changes in functionality to customers. Deployments should be decoupled from releases, which means that code should be able to be deployed to any environment without necessarily changing the feature set that end-users see. Feature flags are a commonly used technique that enables decoupling deployments from releases. Feature flags provide the additional benefit of being able to quickly roll back changes without requiring a software deployment.
Downtime - Automatic deployments at any time of the day help teams stay focused on feature development without worrying about managing releases. The downside, however, is that application deployments can cause downtime at inopportune times. To address this, teams can practice zero-downtime deployment strategies such as canary releases (rolling out changes to a small subset of users) and blue/green deployments (running two separate but identical production environments) to eliminate downtime.
Monitoring and observability - The ability to monitor a running application is critical to achieving continuous deployment. This allows teams to have insight into the health of a running application and intervene when needed, ideally before customers are negatively impacted. Helpful tools include log aggregators like Splunk, APM tools such as NewRelic, and networking, monitoring, and alerting systems such as Nagios.
The biggest hurdle, however, will likely be lack of trust in the software delivery process. Many organizations that do not prioritize automated testing and deployment practices have been driven to implement burdensome change management processes to reduce the risk of problematic production releases. If you feel reluctant to completely automate the deployment, ask yourself why that is. Do you have frequent production bugs? Do you experience significant downtime during releases? Do you experience miscommunication with users? Addressing the problems that lead to these concerns before moving towards a continuous deployment model is essential. In the meantime, you’ll achieve a more mature delivery process, higher confidence in deployments, and a test suite that inspires confidence while your software grows and evolves to meet updated business requirements.
The Best of Both Worlds: CICD
Now that we’ve defined both continuous integration and continuous delivery/deployment, decide if the following statements are true about your organization and software delivery practices:
Your team uses source control to frequently incorporate small changes into a shared codebase.
Your test suite covers the testing pyramid and provides the confidence necessary to quickly evolve your codebase.
You have shifted left on integration and frequently and automatically test integrations with other teams and systems you depend on.
You have a mature pipeline that builds, tests and deploys your changes to deployment environments, including production.
Your downtime is minimal and your development teams can deploy to production at any time of the day.
If you’re doing all of the above, congratulations! You are practicing CICD. And if you need help implementing any of the tools or best practices we’ve shared, the Crafted team would be happy to help. Reach out today!